Redis学习笔记(2)
前方多图提醒,请耐心等待加载或刷新页面,已参考多种资料,作图不易,且看且珍惜。(快累趴了)
Redis主从复制
概述
主从复制,主机数据更新后根据配置和策略,自动同步道备机的master/slaver机制,Master以写为主,Slave以读为主。
其作用有以下几点:
- 读写分离:主服务器负责写,各从服务器负责读,即主机写,从机读
- 容灾快速恢复:主从多台服务器进行持久化操作,任意一台服务器宕机也不会影响数据恢复,有效避免了单点故障问题,使数据持久化更加安全
- 其他:主从复制是实现哨兵模式和Redis集群的前提
实现主从复制
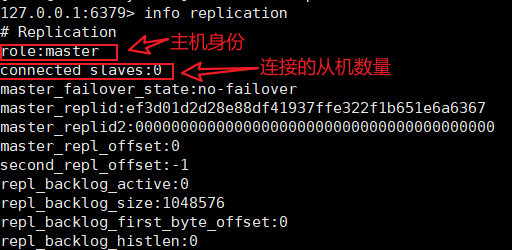
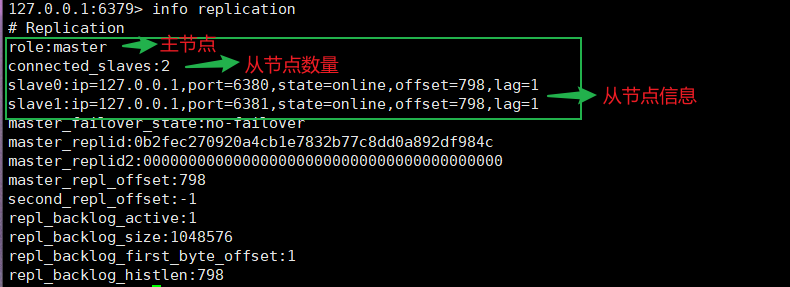
每一台Redis服务器启动时,默认都为主服务器(master),可通过命令info replcation查看
-
配置文件修改
1
2
3mkdir /myredis # 创建文件夹存储配置文件
cd /myredis # 进入文件夹
cp /etc/redis.conf /myredis/redis.conf # 复制原配置文件,以便操作创建
reids6379.conf、reids6380.conf、reids6381.conf文件,在文件中填入以下信息1
2
3
4include /myredis/redis.conf
pidfile /var/run/redis_端口号.pid
port (端口号)
dbfilename dump(端口号).rdb
-
启动redis服务器
新建窗口通过
redis-cli -p 端口号进入各自的客户端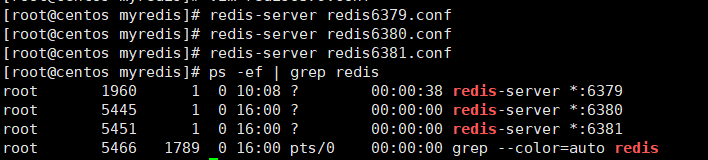
-
使用命令实现主从关系(配从不配主)
1
slaveof <masterip> <masterport>
详情如下图所示
从节点:
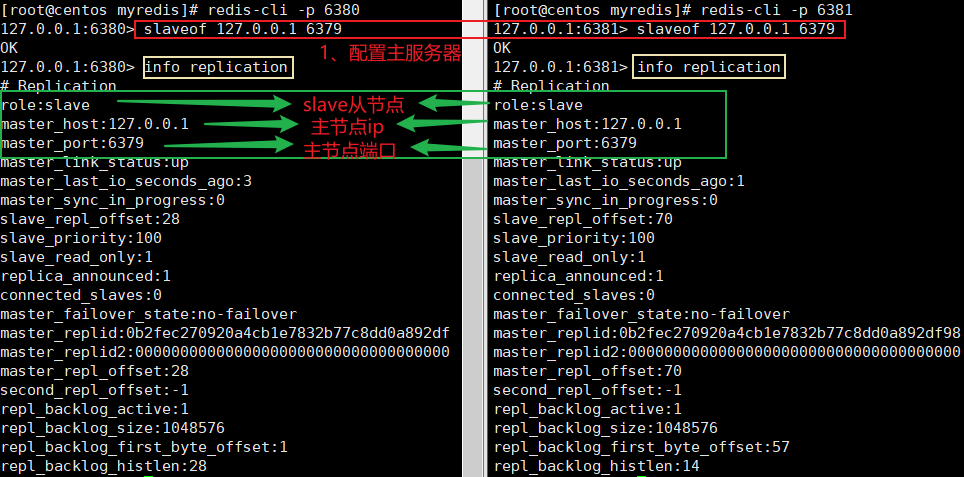
主节点:
-
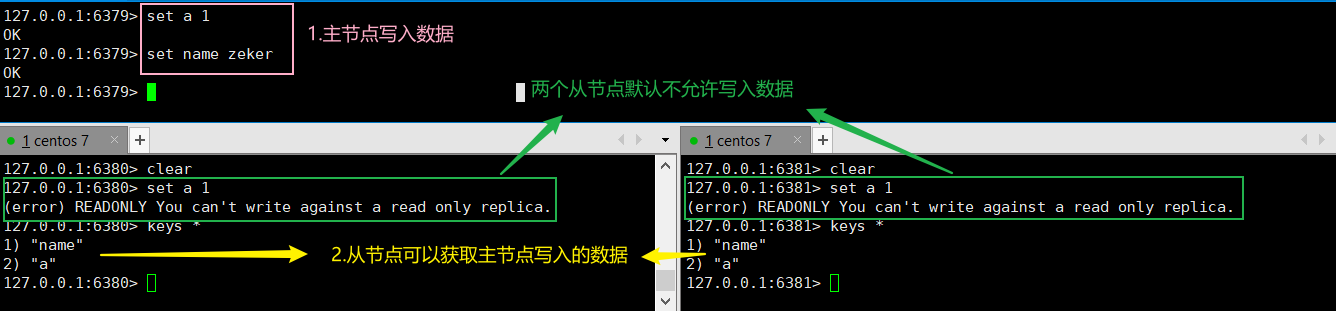
主从关系实现后,验证是否实现数据复制
主从复制原理
在Redis2.8之前同步方式都以全量方式同步,但之后为了提高效率,数据复制方式分为两种:全量复制和部分复制。
- 全量复制:将主服务器中的数据,全部同步到从服务器中,一般是在从服务器启动初始化数据的时候进行全量同步
- 部分复制:将未同步的增量数据,同步到从服务器,无需再全部复制一遍,一般用于因网络中断等无法同步数据的情况下,待恢复正常之后,将中断期间的数据进行部分同步
全量复制图解
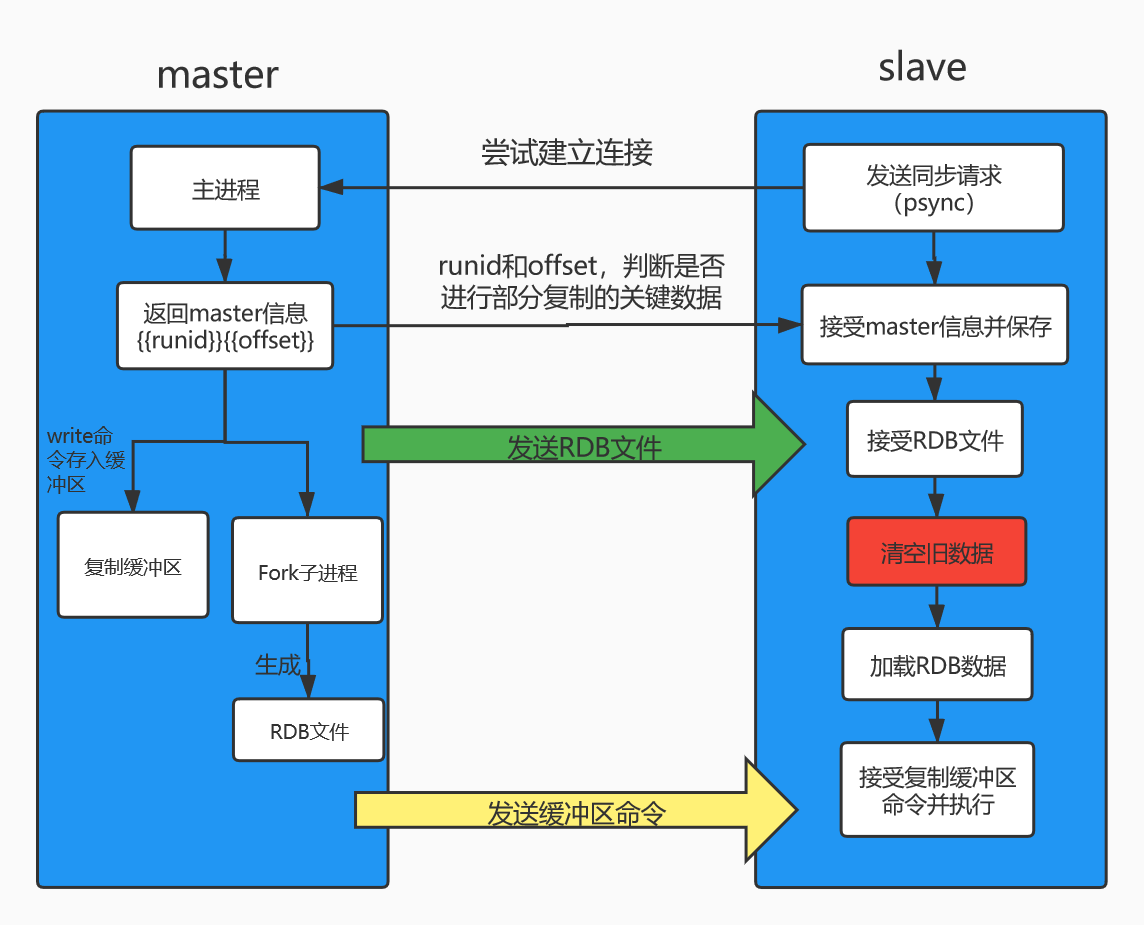
解释说明:
1、从节点断开连接后,发送同步请求psync尝试建立连接
2、主节点向从节点发送信息,获取runid和offset
3、主节点fork子进程将全部数据生成RDB文件
4、主节点期间接收到的write命令存入到复制缓冲区
5、当主节点RDB文件完成后发送给从节点
6、从节点接受RDB文件后,清空旧数据,加载RDB数据到内存中(即直接将其作为数据文件)
7、主节点发送缓冲区内的数据到从节点
8、从节点接受复制缓冲区命令并执行,最后同步到最新数据中
部分复制图解
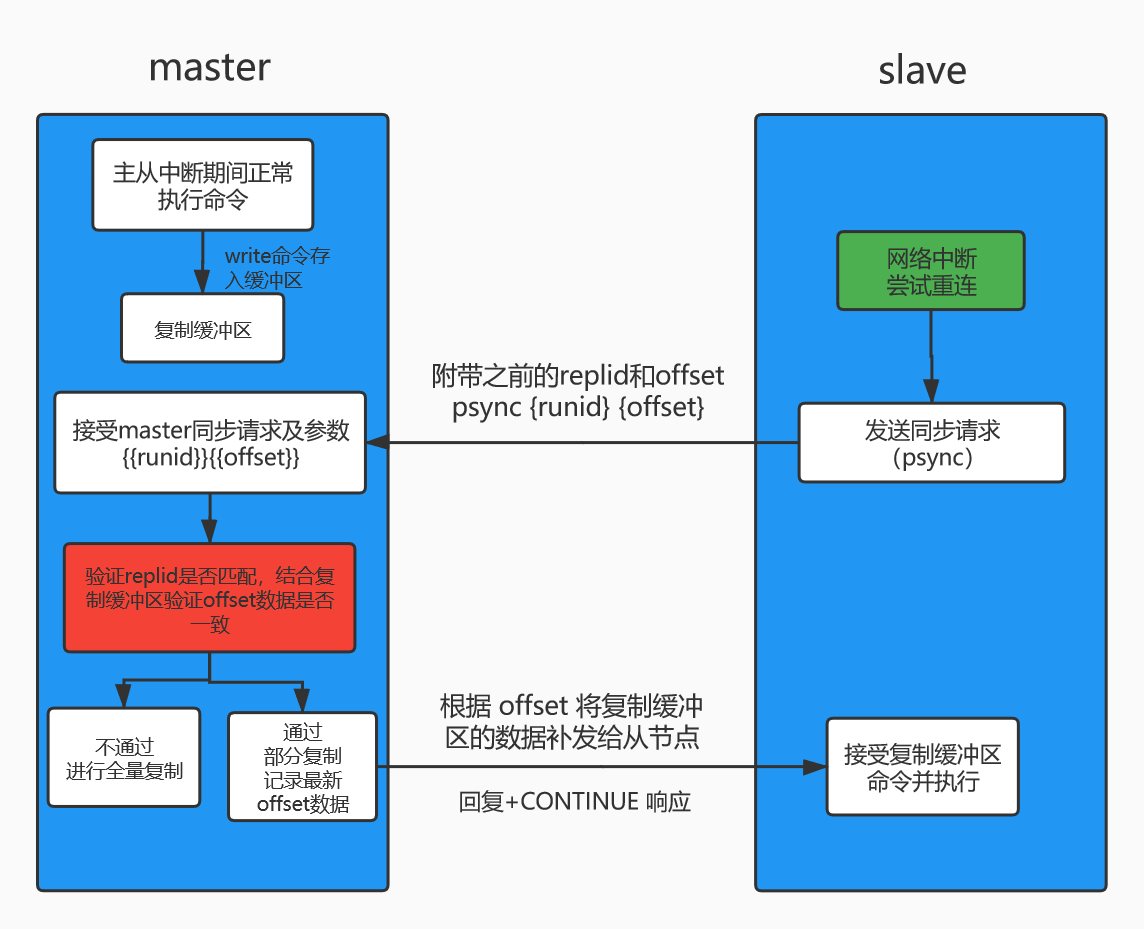
解释说明:
1、当主从服务器之间由于网络中断后,从节点会尝试连接主节点
2、重连期间主节点接收到的write命令会存入到复制缓冲区
3、当网络恢复后,从节点成功连接主节点,由于之前从节点保存了主节点的runid 和offset,所以只需要发送命令 psync {runid} {offset}即可
4、主节点接收到从节点的请求,会先验证请求的runid是否和自身的的 runid匹配,不匹配则进行全量复制,其后查看请求的offset在自身复制缓冲区查找,如果偏移量之后的数据存在缓冲区中,则对从节点发送 +CONTINUE 响应,表示可以进行部分复制。
5、当从节点传递过来的runid和offset验证通过时,则进行部分复制,并记录新的offset
PS:当主机宕机时,主从关系仍存在,各从机中的主机信息不会发生改变,主机重启后,其从机信息与宕机前的一致
模式
一、 薪火相传
有三个节点ABC,A为主机,B为A的从机,C为B的从机。
- 主机A无法对C进行主从复制
- 当主机A存活时,B、C都不可写数据,只能读数据
- 主机A宕机后,B、C仍不可写数据,直到B使用
slaveof no one命令后,即下面所讲的反客为主模式,B可以写数据,C可以读取B写的数据
官方概述:上一个slave(从机)可以是下一个slave(从机)的master(主机),slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个的master,可以有效减轻master的写压力。
风险:一旦某个从机宕机,后面的从机都无法备份。
中途变更转向:会清除之前的数据,重新建立拷贝最新的。
二、 反客为主
当一个master宕机后,后面的slave通过命令可以立刻升为master,其后面的slave不用做任何修改,但不用修改的前提在于从机实现了薪火相传模式,否则仍需进行主从关系确认。
1 | slaveof no one # 将从机变为主机 |
当宕机后的master重启后,此时已无任何主从关系,无任何复制关系。
三、 哨兵模式
哨兵模式,俗称反客为主的自动版,能够后台监控主机是否故障,若故障了则根据投票数自动将从库转换为主库,保证了系统的可用性。
作用
- 监控(Monitoring):哨兵会不断地检查主节点和从节点是否运行正常
- 自动故障转移(Automatic faliover):当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点
- 配置提供者(Configuration provider):客户端在初始化时,通过连接哨兵来获得当前Redis服务的主节点地址
- 通知(Notification):哨兵可以将故障转移的结果发送给客户端
步骤
-
调整为
一主二仆模式,6379带着6380、6381 -
在自定义的
/myredis目录下新建sentinel.conf,切记文件名不能有错 -
配置哨兵
在
sentinel.conf文件中填入配置信息,保存退出1
sentinel monitor mymaster 127.0.0.1 6379 1
注:
mymaster为监控对象起的服务器名称(即哨兵名称),1为至少有多少个哨兵同意迁移的数量 -
启动哨兵
1
redis-sentinel /myredis/sentinel.conf
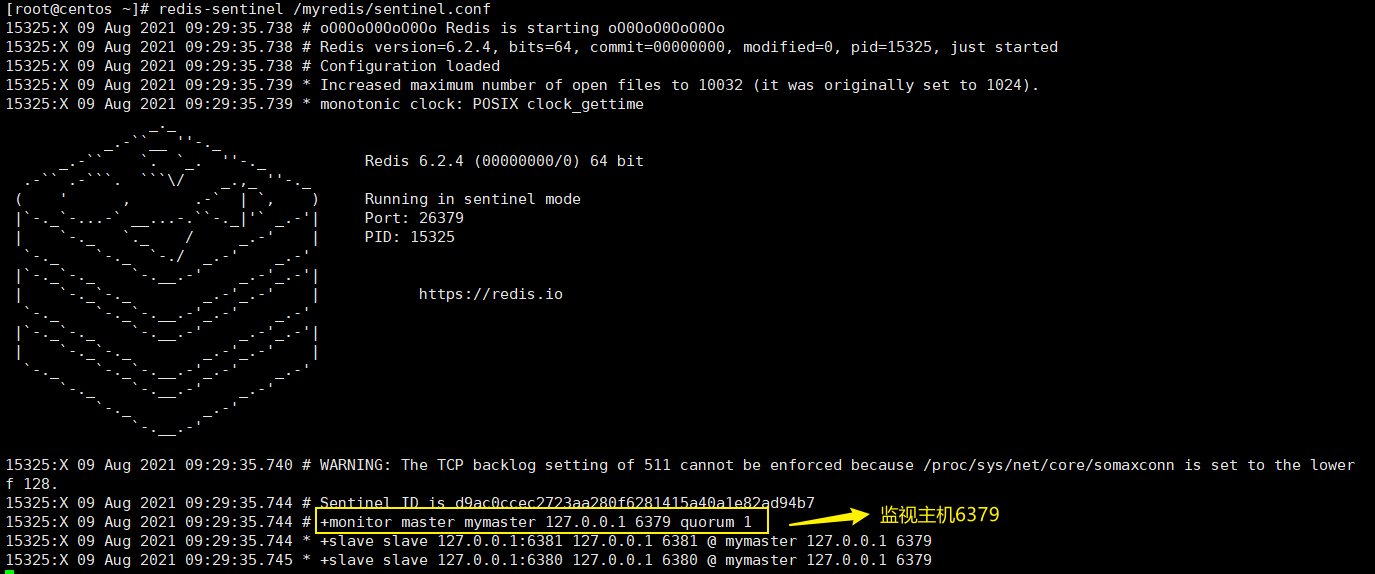
-
当主节点6379宕机后,等待30秒,哨兵进行投票推选新主节点
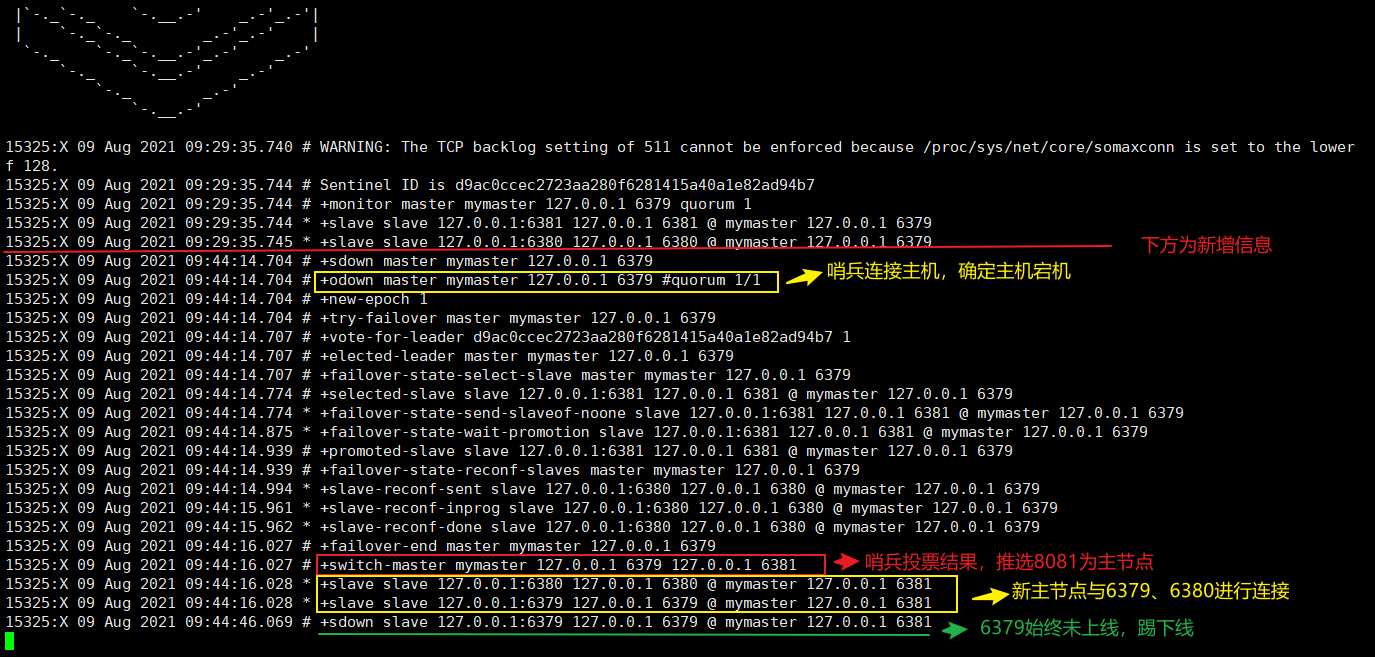
-
当主节点6379重新连接后,哨兵服务端响应两句

第一句是:去除6379的下线处理
第二句是:重连6379到新的主节点上,此时6379为新主节点的从节点
-
检验主从复制是否正常工作

上图所见,主从复制正常运行,至此,哨兵模式的配置完成
优缺点
优点:高可用,读写分离,哨兵模式是基于主从模式的,主从模式的优点,哨兵模式都具备,主从可以自动切换,系统更健壮,可用性更高。
缺点:Redis比较难支持在线扩容,在集群容量达到上线时在线扩容会变得非常复杂。
Redis集群
概述
所谓的集群,就是通过添加服务器的数量,提供相同的服务,从而让服务器达到一个稳定、高效的状态,集群主要解决容量不够和并发写操作压力等问题。
Redis3.0版本之前只支持单例(代理主机),在3.0版本即以后的版本才支持集群,采用无中心化集群配置。
Redis集群,是基于Redis主从复制实现的,同时也存在三种模式:主从模式、哨兵模式和Cluster集群模式。
由于前两种模式在前面主从复制环节中有讲解,所以我们这里重点关注Cluster模式。
Cluster集群模式
- 之前的
哨兵模式基本已经可以实现高可用、读写分离,但是在这种模式每台redis服务器都存储相同的数据,很浪费内存资源,所以在Redis3.0上加入了Cluster集群模式,实现了Redis的分布式存储,也就是说每台Redis节点存储着不同的内容 - 根据官方推荐,集群部署至少要
3台以上的master节点,最好使用3主3从六个节点的模式 - Cluster集群由多个redis服务器组成的
分布式网络服务集群,集群之中有多个master主节点,每一个主节点都可读可写,节点之间会相互通信,两两相连,redis集群无中心节点
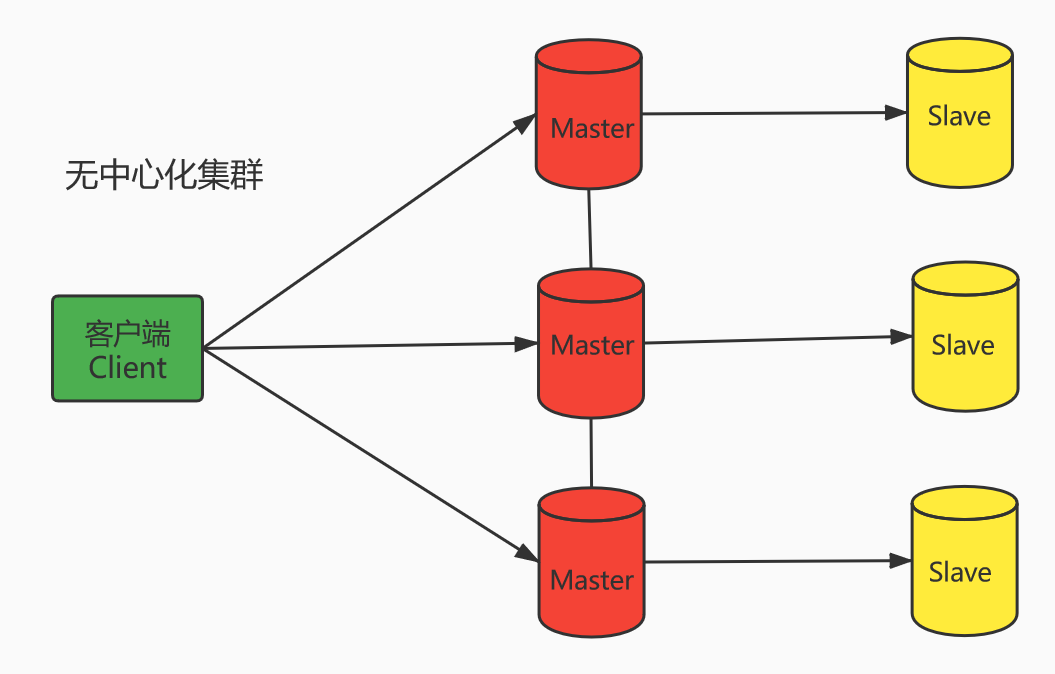
- 在
redis-Cluster集群中,可以给每个主节点添加从节点,主节点和从节点直接遵循主从模型的特性,当用户需要处理更多读请求的时候,添加从节点可以扩展系统的读性能 redis-cluster的故障转移:redis集群的主机节点内置了类似redis sentinel的节点故障检测和自动故障转移功能,当集群中的某个主节点下线时,集群中的其他在线主节点会注意到这一点,并且对已经下线的主节点进行故障转移- 集群进行故障转移的方法和
redis sentinel进行故障转移的方法基本一样,不同的是,在集群里面,故障转移是由集群中其他在线的主节点负责进行的,所以集群不必另外使用redis sentinel
步骤
-
删除持久化数据(rdb/aof文件)
1
2cd /myredis # 进入自定义目录
rm -rf rdb* # 删除rdb文件,如若有aof文件,也一并删除 -
实例准备
Master端口:6379、6380、6381
Slave端口:6389、6390、6391
分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
配置文件
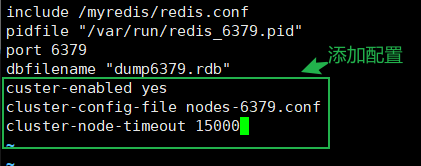
redis6379.conf删除之前的哨兵数据,添加下面的集群配置,保存退出
1
2
3cluster-enabled yes # 打开集群模式
cluster-config-file nodes-6379.conf # 设定节点配置文件
cluster-node-timeout 15000 # 集群节点的超时时限默认值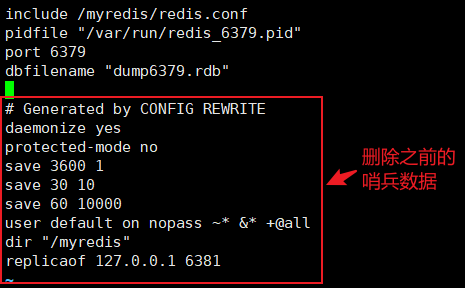
删除原来的
redis6380.conf和redis6381.conf文件,另外拷贝5份修改的redis6379.conf为对应端口号文件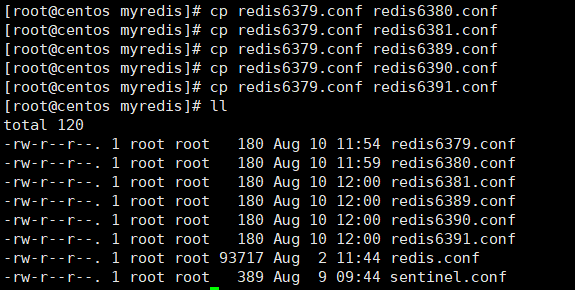
进入vim编辑器,在命令模式下使用
:%s/6379/替换后端口快速修改5份拷贝后的配置文件信息 -
启动6个redis服务
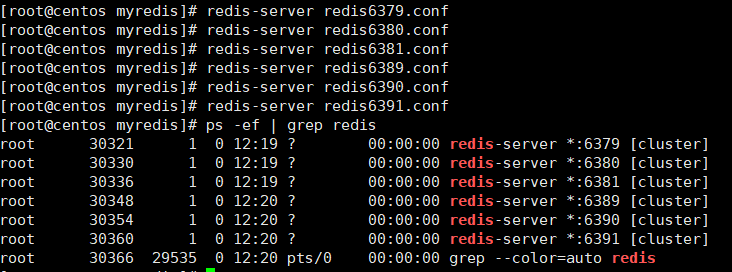
-
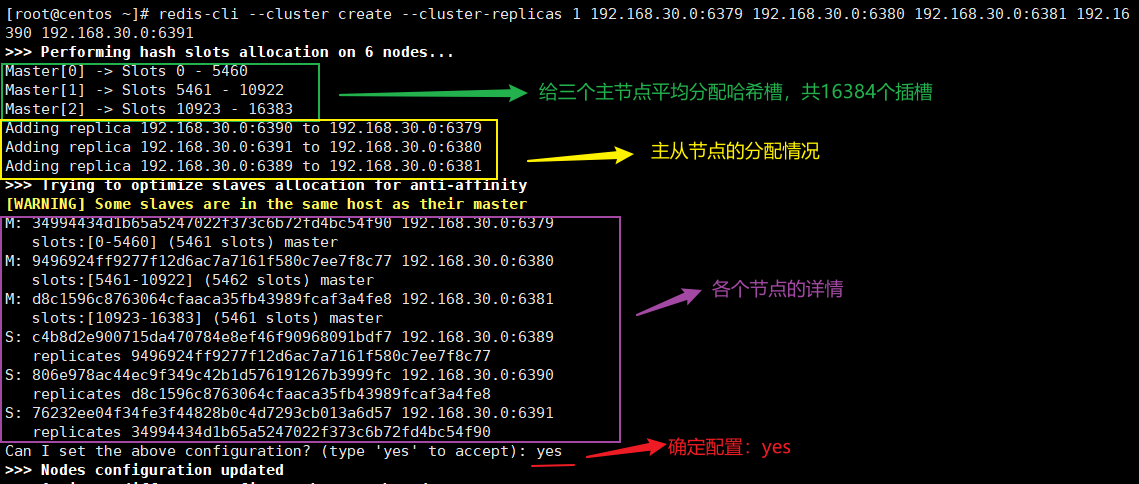
组合集群
组合之前,确保所有redis服务启动后,
nodes-端口号.conf文件都生成正常如果你是redis5.0及之后的,无需安装ruby依赖,redis安装目录里内置了集群命令行工具redis-trib ,它是一个 Ruby 程序, 这个程序通过向实例发送特殊命令来完成创建新集群, 检查群, 或者对集群进行重新分片工作。
1
redis-cli --cluster create 192.168.30.0:6379 192.168.30.0:6380 192.168.30.0:6381 192.168.30.0:6389 192.168.30.0:6390 192.168.30.0:6391 --cluster-replicas 1 # 组合命令
-
测试集群
1
2
3redis-cli -c -p 端口号 # -c参数实现自动重定向,连接客户端
cluster info # 查看集群状态
cluster nodes # 查看节点信息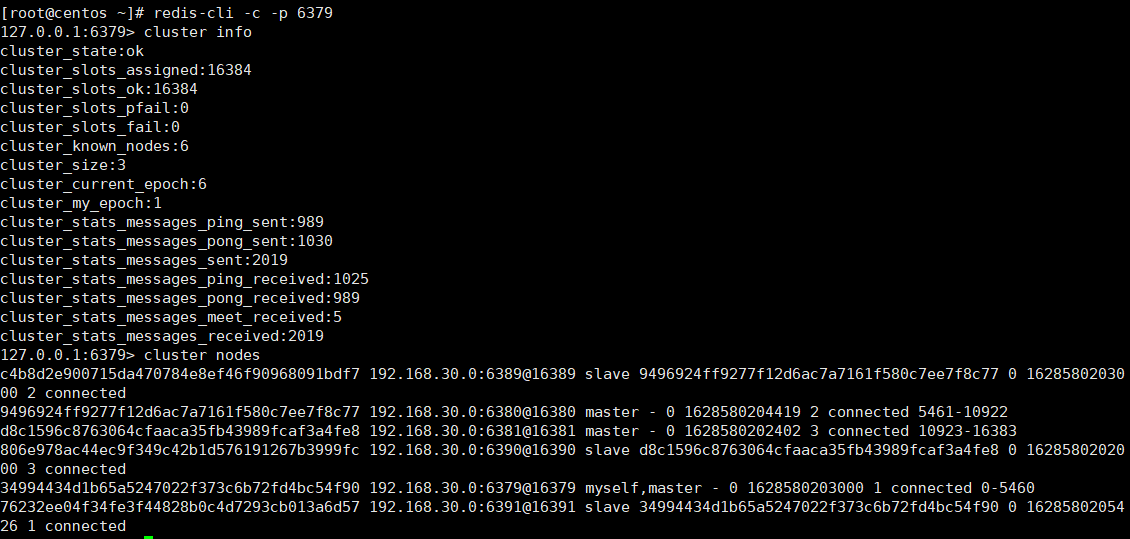
如图所示,集群搭建成功。
尝试往集群中写入数据

不在一个
slot下的键值,是不能使用mget、mset等多键操作,但可通过{}内相同内容的键值对放到同一个slot中去
查询集群中的值
1
2
3cluster keyslot <key> # 计算key的插槽值
cluster countkeysinslot <slot> # 返回slot槽的键数(只能查看自己插槽范围内的值)
cluster getkeysinslot <slot> <count> # 返回count个slot槽中的键 -
集群的Jedis开发
无中心化主从集群。即使连接的不是主机,集群会自动切换主机存储。遵循
主写从读。1
2
3
4
5<!-- jedis依赖包引入 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>1
2
3
4
5
6
7
8
9
10
11public class JedisClusterTest{
publi static void main(String[] args){
Set<HostAndPort> set = new HashSet<HostAndPort>();
set.add(new HashSet<HostAndPort>("192.168.30.0",6379));
JedisCluster jc = new JedisCluster(set);
jc.set("name","zeker");
String value = jc.get("name");
System.out.println(value);
jc.close();
}
}
集群优缺点
优点:实现扩容、分摊压力、无中心配置相对简单
缺点:多键操作、多键的Redis事务、lua脚本均不被支持